Enabling Digital Lexicography through Standardisation



Summary of the Impact
Developed through research led by John McCrae at the University of Galway, OntoLex and DMLex are two standardization efforts, which have transformed the way linguistic data is structured and shared. Before these standards, dictionary data was stored in many incompatible ways, making it hard for different tools and researchers to interoperate and work together. These standards now enable dictionaries and language technologies to seamlessly share data. These standards offer common ways to organize, connect and use language data across different systems. Together, they support modern applications from AI to digital humanities helping researchers create and share language resources.


Research Description
This research describes two closely related initiatives. OntoLex-Lemon was first released on the 10th May 2016 and we describe the extensions that have further developed this model as well as the work we have done to support the adoption of this work. This includes the Lexicography module (released 17th September 2019), the Frequency, Attestation and Corpus Information (FrAC) module (since 2019, currently under public review) and the Morph(ology) module (since 2018, now preparing for public review). This work has been carried out by the Ontology-Lexica Community Group, co-chaired by Dr John P. McCrae at the University of Galway. Secondly, we describe the DMLex (Data Model for Lexicography) model that was developed by the OASIS Lexicographic Infrastructure Data Model and API (LEXIDMA) TC (of which Dr John P. McCrae is a member) and was released as a standard in 2025. The DMLex model is a high-level template for representing dictionary data using common digital formats like XML, JSON, and RDF.
Before the development of OntoLex and DMLex, the field of lexicography faced significant inefficiencies due to fragmented data sharing and a lack of standardized frameworks. Traditional lexicographic methods relied on disparate, often proprietary formats, which hindered interoperability and made it difficult to integrate dictionary data with web technologies or computational tools. In particular, manual reformatting of between different data structures or differences in the modelling would require substantial effort to develop format converters or manually adapt resources.
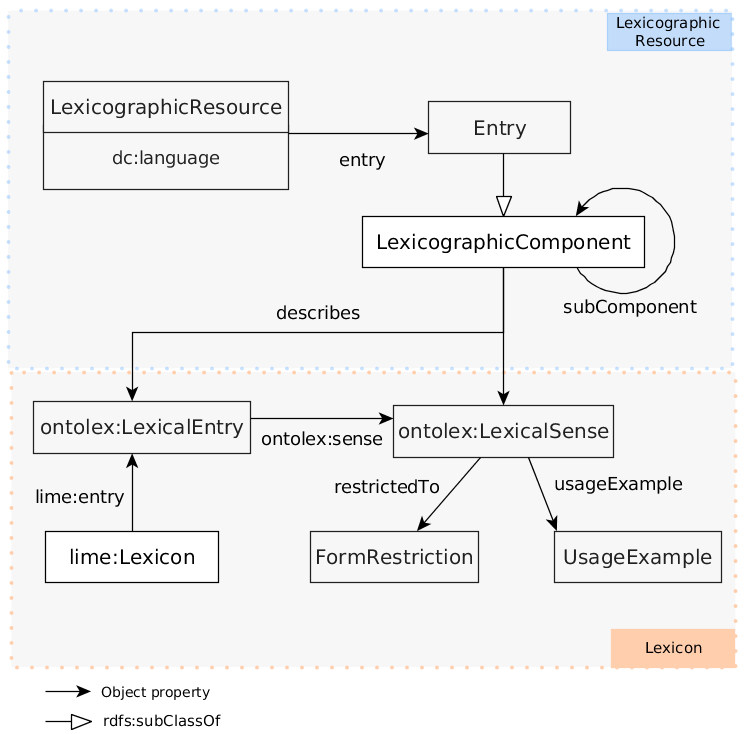
The OntoLex-Lemon Leixcography Module
This module represents a critical advance in linking traditional lexicography with the web, addressing a longstanding challenge: the need for interoperable models for dictionaries compatible with web technologies replacing fragmented early effort.
For example, projects like the Oxford Global Languages ontology and the KDictionaries Global Series employed disparate solutions for defining dictionary entries, leading to inconsistencies in interoperability. This model developed through collaborative efforts a unified structure for dictionary data.
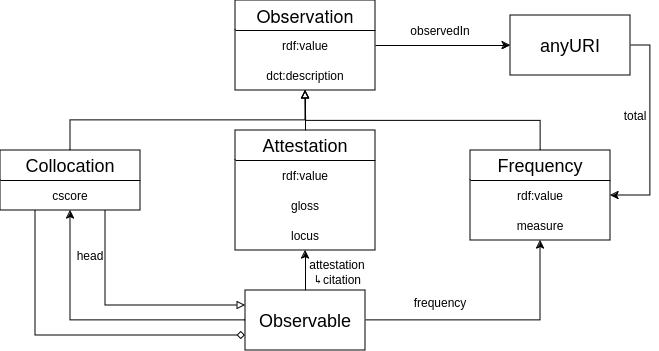
The FrAC Module
This module extended the OntoLex-Lemon model designed to link lexical resources with corpora and other collections of linguistic primary data. This module expands the application domains to support tasks in natural language processing (NLP), AI, and human language technology.
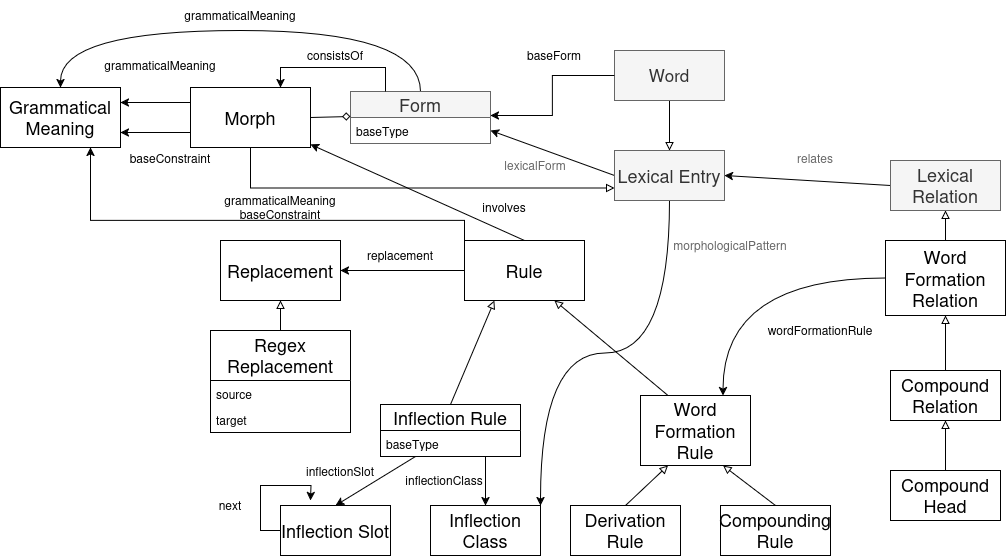
The Morph Module
This module further expands the OntoLex-Lemon framework by introducing comprehensive mechanisms for encoding and processing grammatical changes in the forms of words (morphology).



Cultural Impact
The OntoLex model has been widely adopted by developers of lexicographic resources and has created a wide impact through its adoption. Wikidata, a resource developed by MediaWiki with over 23k active editors and 24 billion monthly page views that contributes structured data to Wikipedia, has incorporated key principles of the OntoLex-Lemon model into its WikibaseLexeme data model, enabling a structured and interoperable approach to represent lexical information. While maintaining its commitment to simplicity and collaborative editing, WikibaseLexeme aligns with OntoLex to support advanced linguistic data modelling while ensuring accessibility for a diverse community of users. Similarly, OntoLex has been adopted by DBnary, a multilingual lexical dataset extracted from various Wiktionary language editions, developed by the GETALP team at the Laboratoire d’Informatique de Grenoble, which provides a standardized and interoperable resource for multilingual language processing. BabelNet, which covers 23 million entries in over 600 languages and has been cited over 1900 times, uses the OntoLex-Lemon model to make its vast multilingual lexicographic and encyclopedic knowledge machine-readable, enabling seamless integration with the web. Finally, the Global Wordnet Association (GWA) has adopted OntoLex as the basis for its interchange format as part of its Collaborative Interlingual Index (CILI) and has been adopted by projects such as Open English WordNet (>500 stars on GitHub), Open Dutch WordNet and DanNet.
Technological Impact
OntoLex has directly benefited researchers in the humanities by supporting their adoption of digital methods. For example, the LiLa project, at the Universita Cattolica del Sacro Cuore, integrates Latin linguistic resources with external datasets by adopting the OntoLex-Lemon vocabulary to describe lexical resources and link them. According to their testimonial -
“From the very inception of the LiLa project, we regarded the use of OntoLex-Lemon as indispensable, given its status as the state-of-the-art module for lexical knowledge representation.”
This innovative digital humanities application has supported classics scholars in advanced research in Latin language and literature, fostering new insights and collaborations, such as the new GLOSSAM project at the University of Galway. Tools such as VocBench, have been developed to support the creation and management of OntoLex-lemon lexicons, providing a collaborative platform for developing lexical resources in RDF format. It has been adopted in terminology, digital humanities and publishing and is managed and supported by the Publications Office of the EU. Similarly, the LexO tool is a collaborative editor for OntoLex developed by the Institute for Computational Linguistics “A. Zampolli”, where they use it to manage resources for ancient languages.
Social Impact
OntoLex has enabled scholars studying under-resourced languages to develop new resources and approaches for integrating and studying their resources. For example, Azin and Ahmadi used the model as part of their documentation of Southern Kurdish languages. In this way, the model has directly contributed to the preservation of endangered languages across the globe.
Commercial Impact
DMLex has already seen adoption, especially by Sketch Engine, a leading corpus management and text analysis tool used for linguistic research, lexicography, and language education.
"Has had a transformative effect on the infrastructure of Lexical Computing’s key products … [and] tools [which] serve thousands of users in research, publishing, and education"
Sketch Engine leverages DMLex to structure its lexicographic outputs and facilitate interoperability with other lexicographic and linguistic resources. In particular, the development of Lexonomy, an online dictionary authoring tool is based on DMLex and their novel “one-click” dictionary development methodology aims to leverage AI to accelerate the development of dictionaries.






Revolutionising Lexicography for the Digital Age
Finally, OntoLex and DMLex are both contributing to a sea change in lexicography, where:
“the shift from unstructured to structured data, technological innovations, and the emergence of publicly accessible, interlinked data about language, have led to an increased awareness of the need for more stable and established encoding formats for lexicographic data… [and] more and more lexicographic institutions and dictionary publishers are moving away from stand-alone resources (in different encodings) towards centralised lexicographic knowledge bases.”
This can be seen by the wide interest in both models. The Ontology-Lexica Community Group currently has 150 participants from academia and industry and has been a core to two COST actions, Nexus Linguarum on Web-centred linguistic data science and GOBLIN on large-scale, cross-domain and multilingual open knowledge graphs. These open standards are adopted in enterprise such as by Lexical Computing where
“the alignment of DMLex with the OntoLex-Lemon framework has helped bridge the gap between traditional lexicography and linked open data paradigms, opening Lexical Computing’s tools to broader technological ecosystems.”


Testimonial 1
Prof Marco Passarotti
Università Cattolica del Sacro Cuore




Testimonial 2
"The adoption of the DMLex standard, initiated under the ELEXIS project, has had a transformative effect on the infrastructure of Lexical Computing’s key products, particularly Sketch Engine and Lexonomy. These tools serve thousands of users in research, publishing, and education, and the integration of DMLex has enabled the encoding, sharing, and reusability of lexical resources at an unprecedented scale. The model’s emphasis on interoperability has significantly streamlined workflows and facilitated new AI-driven lexicographic functionalities, such as automated dictionary compilation and enhanced corpus-based analysis."


"Moreover, the alignment of DMLex with the OntoLex-Lemon framework has helped bridge the gap between traditional lexicography and linked open data paradigms, opening Lexical Computing’s tools to broader technological ecosystems. This standardization has reduced development overhead and improved data portability across diverse lexicographic platforms, further reinforcing the company’s position as a leader in computational lexicography. Through these standards, Lexical Computing has not only enhanced its service offering but has actively contributed to setting new benchmarks in the digital treatment of lexical data."
Research Funding



This research was supported by funding from Taighde Éireann – Research Ireland, the Horizon 2020 Framework Programme (through the ELEXIS project) and COST (European Cooperation in Science and Technology). The work was supported by the Insight Research Centre for Data Analytics, funded by Taighde Éireann – Research Ireland


References to the Research
- Modelling Frequency and Attestations for OntoLex-Lemon. Christian Chiarcos, Maxim Ionov, Jesse de Does, Katrien Depuydt, Anas Fahad Khan, Sander Stolk, Thierry Declerck and John Philip McCrae Proceedings of the Globalex Workshop on Linked Lexicography (@LREC 2020), pp 1-9, (2020). DOI:
- Challenges for the Representations for Morphology in Ontology Lexicons. Bettina Klimek, John P. McCrae, Maxim Ionov, James K. Tauber, Christian Chiarcos, Julia Bosque-Gil and Paul Buitelaar Proceedings of Sixth Biennial Conference on Electronic Lexicography, eLex 2019, (2019)
- The OntoLex-Lemon Model: development and applications. John P. McCrae, Julia Bosque-Gil, Jorge Gracia, Paul Buitelaar and Philipp Cimiano Proceedings of eLex 2017, pp 587-597, (2017)
- The OntoLex Lemon Lexicography Module. Julia Bosque-Gil, Jorge Gracia, John McCrae, Philipp Cimiano, Sander Stolk, Fahad Khan, Katrien Depuydt, Jesse de Does, Francesca Frontini, Ilan Kernerman. W3C Final Community Group Report, 17 September 2019.
- The Ontolex Module for Frequency, Attestation and Corpus Information. Christian Chiarcos, John P. McCrae, Besim Kabashi, Fahad Khan, Ciprian-Octavian Truică, Katerina Gkirtzou, Sander Stolk, Thierry Declerck, Jesse de Does, Katrien Depuydt, Elena-Simona Apostol, Max Ionov. W3C Draft Community Group Report. 10 December 2024.
- Data Model for Lexicography (DMLex) - Version 1.0. Michal Měchura, David Filip, Miloš Jakubíček, Vojtěch Kovář, Simon Krek, John McCrae. Committee Specification 01, OASIS Open, 8 November 2024.


Evidence of Impact
- https://www.mediawiki.org/wiki/Extension:WikibaseLexeme/Data_Model
- Gilles Sérasset. DBnary: Wiktionary as a Lemon-based multilingual lexical resource in RDF. Semantic Web 6(4): 355-361 (2015). https://doi.org/10.3233/SW-140147
- https://babelnet.org/about
- https://globalwordnet.github.io/schemas/
- GLOSSAM Project (Pádraic Moran, University of Galway)
- https://lila-erc.eu/#page-top
- https://sinaahmadi.github.io/docs/articles/azin2021sk.pdf
- https://vocbench.uniroma2.it/
- https://github.com/cnr-ilc/LexO-lite
- https://academic.oup.com/ijl/advance-article/doi/10.1093/ijl/ecae016/7863352
